

TL;DR: Monitorar pipelines no nível de atividade é inviável com ferramentas nativas quando há dezenas de pipelines em múltiplos ambientes. Este artigo apresenta um framework que captura falhas de atividades, padroniza os payloads e os envia para o Azure Monitor via Logs Ingestion API, permitindo consultas KQL, dashboards e alertas baseados em padrões. A abordagem complementa o monitoramento nativo e transforma falhas em um dataset centralizado, viabilizando análise de confiabilidade cross-pipeline e redução proativa de incidentes.
Introdução
Plataformas de dados modernas não se resumem mais a mover e transformar dados. Em produção, o que realmente importa é a confiabilidade e a velocidade com que se entende e reage quando algo quebra.
Se você usa Azure Synapse, ADF ou Microsoft Fabric, já tem monitoramento embutido — consegue ver execuções de pipelines e mensagens de erro. Mas isso não mostra erros no nível de atividade. O monitoramento de pipelines funciona bem para depurar uma falha isolada, mas não escala.
Quando você tem dezenas de pipelines rodando em vários ambientes, as falhas se tornam difíceis de rastrear. Você pula entre execuções, examina saídas de atividades e tenta montar o quebra-cabeça. De repente, perguntas simples ficam difíceis de responder:
- Quais datasets estão falhando com mais frequência?
- As falhas estão concentradas nas camadas Bronze, Silver ou Gold?
- Isso é um problema pontual ou um padrão recorrente?
- O que mudou entre ontem e hoje?
Nesse ponto, o monitoramento no nível do pipeline não é mais suficiente. Você precisa de algo mais estruturado.
Observação: O framework pode ser implementado tanto em ambientes Synapse quanto Microsoft Fabric com mudanças mínimas.
Por que precisamos de um framework de logging customizado?
O problema central é que as falhas de pipeline são tratadas como eventos de runtime, não como dados. Elas vivem na saída do pipeline e estão atreladas a uma execução específica. Isso dificulta consultas ao longo do tempo, agregação entre pipelines, correlação entre ambientes, entendimento de quais atividades falharam dentro do pipeline e integração consistente com alertas e dashboards.
Falhas de pipeline são visíveis, mas falhas de atividades não são — e não são operacionalizadas. O que falta é um local central onde todas as falhas sejam capturadas em um formato consistente e estruturado, independentemente de qual pipeline ou dataset as produziu, incluindo logs no nível de atividade.
É aí que entra um framework de logging customizado. Em vez de depender apenas do monitoramento nativo, você introduz uma camada que captura falhas como eventos estruturados, padroniza o payload entre pipelines e o envia para o Log Analytics, onde pode ser consultado com KQL.
Isso muda o modelo: em vez de verificar um pipeline quando ele falha, você trata as falhas como um dataset que pode ser analisado, monitorado e melhorado ao longo do tempo. Com essa mudança, é possível construir alertas baseados em padrões, em vez de reagir a falhas isoladas; rastrear confiabilidade por dataset ou domínio; e identificar problemas recorrentes em vez de lidar com incidentes um a um.
Também muda quem pode usar os dados: a visibilidade não fica mais restrita a engenheiros vasculhando execuções de pipelines — torna-se acessível em nível de plataforma para líderes e stakeholders.
Esse framework não substitui o monitoramento do Synapse. Ele o complementa, adicionando uma camada adequada de observability.
Arquitetura
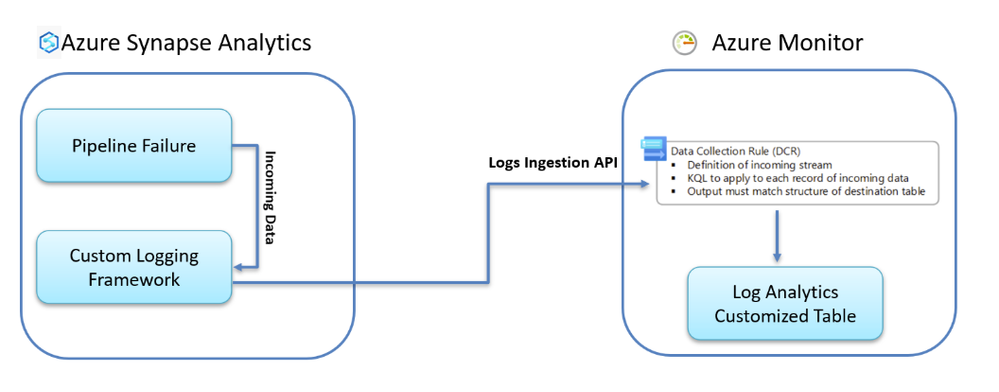
Quando um pipeline falha no Synapse, a falha é interceptada por um caminho dedicado de falha. Neste estágio, não apenas registramos o erro como está — passamos por um framework de logging customizado que transforma a falha em um payload estruturado.
Esse payload inclui contexto chave: nome do pipeline, atividade, ambiente, dataset, camada (Bronze/Silver/Gold), detalhes do erro e identificadores de correlação. O importante aqui é a consistência: cada pipeline emite o mesmo schema, independentemente de sua lógica.
Depois que o payload é construído, ele é enviado ao Azure Monitor usando a Logs Ingestion API. Essa API atua como ponto de entrada no sistema de monitoramento e desacopla os pipelines da implementação de armazenamento subjacente.
Um Data Collection Rule (DCR) fica atrás da camada de ingestão e define como os dados recebidos são tratados. Ele atua como um contrato para o schema do payload e, opcionalmente, aplica transformações antes da persistência.
Finalmente, os logs são armazenados em uma tabela customizada do Log Analytics, onde se tornam totalmente consultáveis com KQL. Neste ponto, as falhas não estão mais atreladas a uma única execução de pipeline — fazem parte de um dataset centralizado que pode ser analisado entre tempo, ambientes e domínios.
Como configurar o Log Analytics?
Antes de integrar o framework com o Synapse, precisamos configurar o destino dos logs: criar um workspace do Log Analytics, definir uma tabela customizada e configurar o caminho de ingestão usando um Data Collection Rule (DCR). O objetivo é criar um pipeline onde eventos de falha estruturados possam ser recebidos, validados e armazenados em formato consistente.
Nota: Todos os passos podem ser automatizados com ARM templates.
1. Criar um workspace do Log Analytics
No Portal do Azure: Azure Monitor → Log Analytics workspaces → criar novo workspace na subscription e região desejadas. Escolha um nome significativo (ex.: log-analytics-data-domain). Esse workspace será o repositório central de todas as falhas de pipeline.
2. Criar uma tabela customizada para falhas de pipeline
Em vez de usar tabelas genéricas, definimos uma tabela dedicada. No workspace: Tables → Create → Custom table (DCR-based). Defina um nome como DataDomain_SynapsePipelineErrors_CL (obrigatório terminar com _CL).
Nesta etapa, defina o schema do payload. Campos típicos:
- TimeGenerated
- PipelineName
- PipelineRunId
- ActivityName
- ActivityType
- Status
- ErrorCode
- ErrorMessage
- Severity
- Environment
- Layer
- DatasetName
- PartitionDate
- WorkspaceName
- CorrelationId
A chave é a consistência: esse schema será reutilizado em todos os pipelines.
3. Criar um Data Collection Rule (DCR)
O DCR define como os dados são ingeridos no Log Analytics. Ele atua como contrato de schema e mecanismo de roteamento. No Portal: Azure Monitor → Data Collection Rules → criar novo DCR e associá-lo ao workspace.
Dentro do DCR: definir um custom stream (ex.: DataDomain_SynapsePipelineErrors_CL), mapear esse stream para a tabela customizada e, opcionalmente, definir transformações usando KQL (renomear campos, forçar tipos).
Esse passo é crítico porque desacopla os pipelines da camada de armazenamento. Se o schema evoluir, você pode ajustá-lo aqui sem alterar a lógica dos pipelines.
4. Configurar o endpoint de Logs Ingestion
Após criar o DCR, o Azure gera um endpoint de ingestão. O padrão é:
https://<dce>.<region>.ingest.monitor.azure.com/dataCollectionRules/<dcrId>/streams/<streamName>?api-version=2023-01-01
Esse endpoint será chamado pelo pipeline Synapse usando uma Web Activity. Neste ponto, habilite a autenticação via Managed Identity e conceda permissão ao workspace do Synapse para enviar dados ao DCR. Isso garante ingestão segura sem secrets.
5. RBAC para Managed Identity
A Managed Identity usada pelo Synapse ou Microsoft Fabric precisa da role Monitoring Metrics Publisher no recurso do DCR. Sem essa atribuição, as requisições à Logs Ingestion API falharão com erro HTTP 403.
6. Validar a configuração
Antes de integrar com pipelines, envie um payload de teste (via Postman ou script) e consulte a tabela:
DataDomain_SynapsePipelineErrors_CL | take 10
Se tudo estiver correto, os registros de teste aparecerão.
Como integrar com pipelines Synapse?
Agora que a camada de ingestão está pronta, o próximo passo é conectar os pipelines do Synapse para que as falhas sejam registradas automaticamente. A ideia é simples: quando uma atividade de pipeline falha, capturamos os detalhes, transformamos em um payload estruturado e enviamos diretamente para a Logs Ingestion API. Isso transforma falhas de pipeline em eventos operacionais centralizados.
1. Adicionar um caminho de tratamento de falha
Dentro do pipeline Synapse, adicione uma dependência On Failure às atividades que deseja monitorar. Normalmente, isso inclui atividades críticas como Copy Activities, execuções de Notebook, Stored Procedures, Data Flows e Web Activities.
Em vez de deixar o pipeline falhar silenciosamente, o caminho de falha redireciona a execução para uma etapa de logging dedicada. Em ambientes de produção, isso é implementado como um pipeline filho reutilizável (ex.: Customized Logs API), mantendo a lógica centralizada e evitando duplicação.

2. Passar metadados de falha como parâmetros
O pipeline de logging deve receber contexto operacional do pipeline pai. Parâmetros típicos incluem: Pipeline name, Pipeline run ID, Activity name, Activity type, Error code, Error message, Environment, Layer (Bronze/Silver/Gold), Dataset name, Severity, Correlation ID.
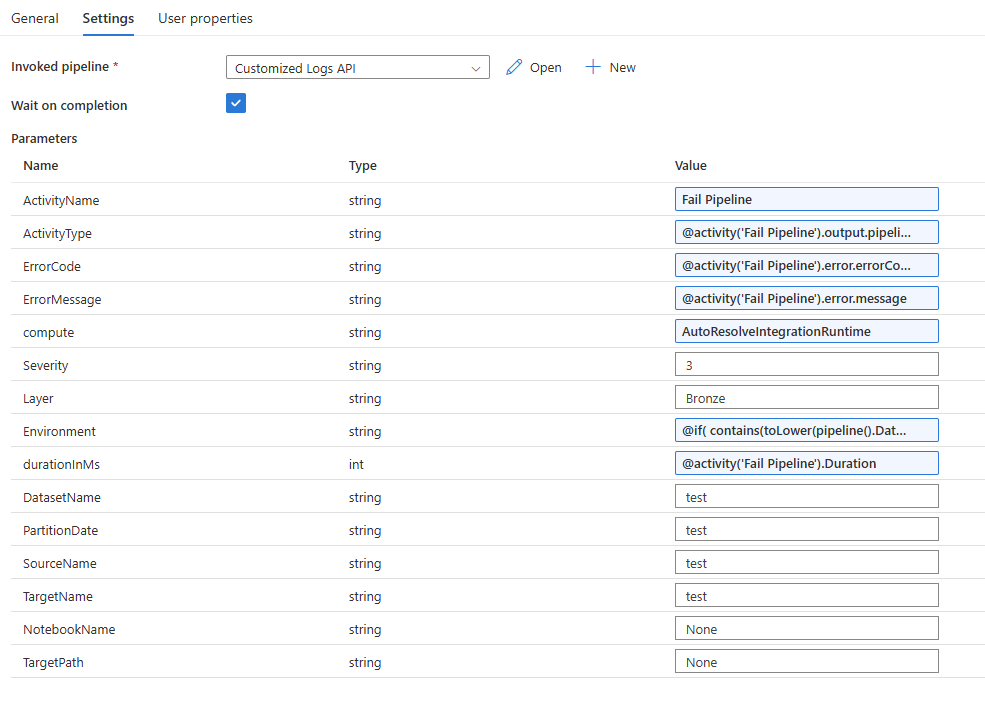
Esses metadados são a base do payload estruturado. Quanto mais contexto operacional você capturar aqui, mais fácil será a troubleshooting futura.
3. Construir o payload de logging
Dentro do pipeline Customized Logs API, use uma expressão de conteúdo dinâmico para construir um JSON que corresponda ao schema do Log Analytics. Exemplo de payload:
concat( '[{"TimeGenerated":"', utcNow(), '","PipelineName":"POC_Test"', ',"PipelineRunId":"', pipeline().RunId, '","PipelineStatus":"Failed"', ',"ActivityName":"TestActivity"', ',"ActivityType":"Web"', ',"ActivityStatus":"Failed"', ',"ErrorCode":"TEST"', ',"ErrorMessage":"POC test"', ',"Severity":"Warning"', ',"Environment":"Test"', ',"Layer":"Bronze"', ',"ExecutionStage":"POC"', ',"DatasetName":"TestDataset"', ',"PartitionDate":"', utcNow(), '","WorkspaceName":"', pipeline().DataFactory, '","TriggerName":"Manual"', ',"TriggerTimeUtc":"', utcNow(), '","DurationMs":1000', ',"RetryCount":0', ',"Compute":"Synapse"', ',"CorrelationId":"', pipeline().RunId, '","Payload":{"source":"test","target":"loganalytics"}}]' )
O importante é a consistência do schema. Cada pipeline deve emitir a mesma estrutura de payload, independentemente de qual atividade falhou. Isso facilita consultas e dashboards downstream.
4. Enviar logs usando uma Web Activity
Após construir o payload, use uma Web Activity para enviar os dados ao endpoint da Logs Ingestion API configurado anteriormente.
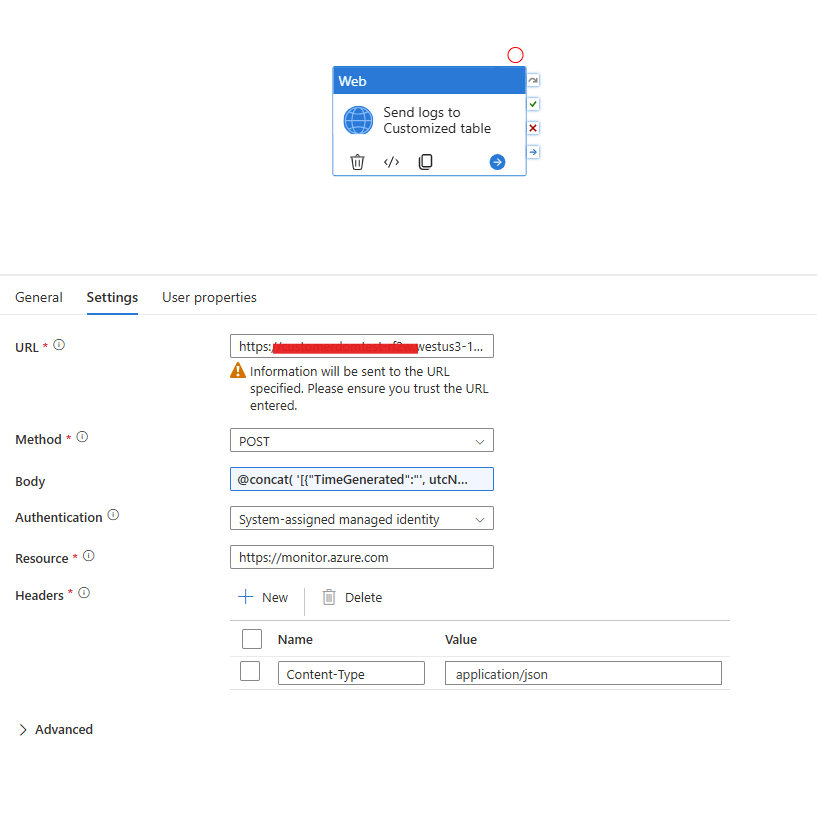
Configuração típica:
- URL:
https://<data-collection-endpoint>.<region>.ingest.monitor.azure.com/dataCollectionRules/<dcr-id>/streams/<stream-name>?api-version=2023-01-01 - Method: POST
- Authentication: Managed Identity
- Resource:
https://monitor.azure.com - Headers:
{ "Content-Type": "application/json" } - Body: Payload JSON dinâmico gerado no passo anterior.
Recomenda-se usar Managed Identity para evitar armazenar secrets ou credenciais dentro dos pipelines, mantendo a autenticação totalmente gerenciada pelo Azure.
5. Validar a ingestão de ponta a ponta
Assim que o pipeline estiver conectado, dispare uma falha controlada e verifique se o evento aparece no Log Analytics:
DataDomain_SynapsePipelineErrors_CL | sort by TimeGenerated desc | take 20
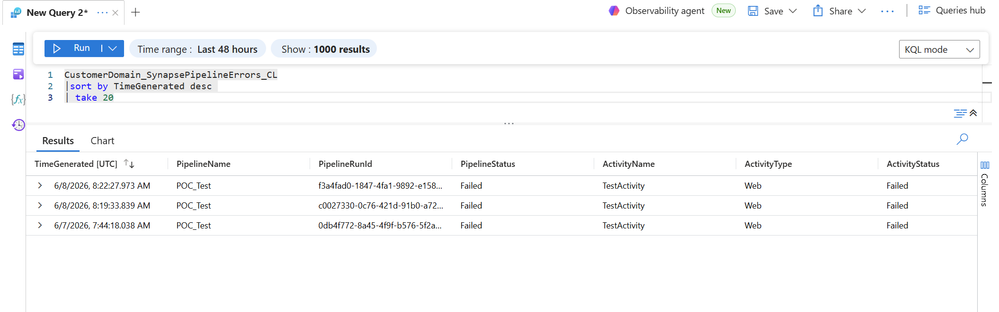
Agora você verá falhas reais de pipeline chegando automaticamente do Synapse. Neste ponto, o framework está operacional: as falhas não são mais eventos de runtime isolados — são registros operacionais centralizados e consultáveis em toda a plataforma.
Próximos passos
Com o framework de logging centralizado em funcionamento, é possível avançar para dashboards operacionais no Power BI ou Microsoft Fabric para analisar tendências de confiabilidade em toda a plataforma de dados. Em vez de reagir a falhas isoladas, agregue logs entre pipelines, datasets, ambientes e camadas medallion para identificar o que realmente causa instabilidade ao longo do tempo.
Isso permite que equipes de engenharia detectem padrões recorrentes de erro, identifiquem datasets instáveis, meçam a confiabilidade da plataforma, analisem picos de falhas após deployments e entendam onde os gargalos operacionais estão concentrados. Ao transformar falhas de pipeline em telemetria operacional estruturada, o framework evolui além do simples logging para uma verdadeira plataforma de observability que suporta engenharia proativa de confiabilidade, com KPIs mensuráveis como tendências de falha, MTTR, conformidade com SLA, distribuição de severidade e health scoring de pipelines.
Links
- Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Azure portal)
- Medallion Architecture Understanding with Azure Synapse Analytics Example
- Feedback: Sally Dabbah | LinkedIn
Perguntas Frequentes
-
Por que o monitoramento nativo de pipelines não é suficiente para ambientes com dezenas de pipelines?
O monitoramento nativo mostra erros no nível do pipeline, mas não captura falhas de atividades individuais de forma estruturada. Em escala, isso torna impossível consultar falhas ao longo do tempo, agregar por dataset ou correlacionar entre ambientes. O framework resolve isso tratando falhas como dados, não como eventos de runtime. -
Quais são os passos principais para configurar esse framework no Azure?
Criar um Log Analytics workspace, definir uma tabela customizada (com sufixo _CL), configurar um Data Collection Rule (DCR) com um stream personalizado, e habilitar a autenticação via Managed Identity. Depois, integrar o pipeline Synapse com um caminho de falha que envia o payload via Web Activity para o endpoint de ingestão. -
Esse framework funciona tanto no Azure Synapse quanto no Microsoft Fabric?
Sim, conforme o artigo, o framework pode ser implementado em ambos os ambientes com mudanças mínimas, pois a lógica de captura e envio é desacoplada do pipeline específico. -
Qual o papel do Data Collection Rule (DCR) nessa arquitetura?
O DCR atua como um contrato de schema e mecanismo de roteamento. Ele define como os dados são ingeridos, mapeia o stream para a tabela customizada e permite transformações opcionais via KQL. Isso desacopla os pipelines da camada de armazenamento, facilitando evolução do schema. -
Como garantir segurança na ingestão de logs sem usar secrets?
Utilizando Managed Identity para autenticar a chamada à Logs Ingestion API. O Synapse ou Fabric precisa da role 'Monitoring Metrics Publisher' no DCR. Isso elimina a necessidade de armazenar credenciais nos pipelines.
Artigo originalmente publicado por Sally Dabbah em Azure Updates - Latest from Azure Charts.
