

Muitas organizações estão adotando o Microsoft Fabric como plataforma unificada de analytics para ingerir dados streaming e batch no Azure Databricks. Neste artigo, analisamos as cinco rotas específicas do Fabric que conectam OneLake/ADLS ao Databricks, detalhando a medallion architecture e os impactos práticos para times de engenharia e gestores de TI no Brasil.
TL;DR: Este artigo detalha as cinco formas de conectar Microsoft Fabric (via Mirroring, RTI, Data Factory e OneLake) ao Azure Databricks para processamento de dados streaming e batch usando a medallion architecture. A conclusão principal é que a abordagem permite unificar dados em tempo real e históricos sem duplicação, com governança via Purview e segurança integrada, sendo ideal para cenários regulados como saúde e finanças.
Como a medallion architecture estrutura os dados?
O fluxo a seguir corresponde ao diagrama de arquitetura:
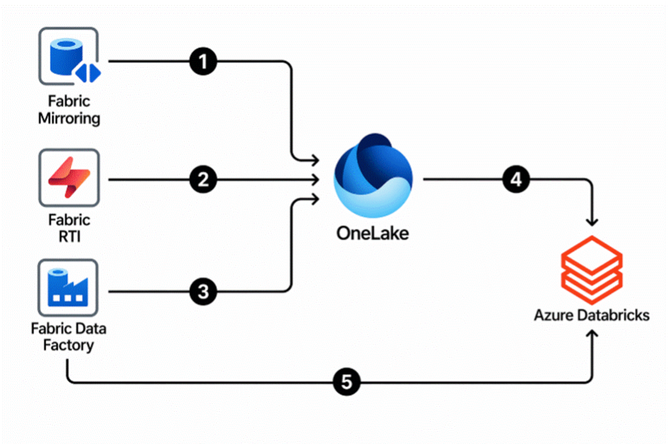
Os dados são ingeridos pelo Microsoft Fabric (via Mirroring, RTI ou Data Factory) e depositados no OneLake/ADLS. Com o padrão medallion, composto pelas camadas Bronze, Silver e Gold, as organizações ganham flexibilidade e extensibilidade no processamento:
- Bronze – Ponto de entrada de dados brutos. Os dados chegam em seu formato original e são convertidos para o formato Delta Lake aberto e transacional.
- Silver – Otimizado para BI e data science. Tarefas de ETL e stream processing filtram, limpam, transformam, juntam e agregam dados Bronze em datasets curados usando SQL, Python, R ou Scala.
- Gold – Dados enriquecidos prontos para analytics e reporting. Analistas usam Power BI, PySpark, SQL ou Excel para insights e consultas.
Quais os cinco caminhos de integração do Fabric para o Azure Databricks?
Nota: Esta arquitetura estabelece um loop-back completo entre Microsoft Fabric e Azure Databricks, permitindo que tabelas da camada Gold sejam espelhadas de volta para o Fabric para criação de dashboards via Azure Databricks Mirroring.
Os cinco caminhos a seguir conectam o Microsoft Fabric ao Azure Databricks:
- Fabric Mirroring para OneLake – Solução turnkey de baixo custo e baixa latência que cria uma réplica de dados de fontes operacionais (SQL Server, Azure Cosmos DB, Oracle) no OneLake. Gerencia automaticamente a carga inicial e as alterações CDC, mantendo os dados continuamente atualizados.
- Fabric RTI para OneLake – Fabric Real-Time Intelligence ingere dados streaming de eventos no OneLake com latência subsegundo, permitindo analytics em tempo real em streams ao vivo.
- Fabric Data Factory para OneLake – Orquestra a ingestão de diversas fontes não cobertas pelo Mirroring (como Sybase ou REST APIs) e deposita os dados no OneLake, garantindo cobertura completa.
- OneLake para Azure Databricks – Conexões do Unity Catalog para OneLake, protegidas via Managed Identities do Microsoft Entra ID, permitem que o Databricks consulte itens do OneLake como catálogo nativo sem duplicação de dados.
- Fabric Data Factory para Azure Databricks (direto) – Orquestra a ingestão de diversas fontes diretamente no Azure Data Lake Storage (ADLS), onde o Azure Databricks coleta os dados para processamento na medallion architecture.
Requisitos específicos: ingestão, armazenamento, segurança, governança e monitoramento
Ingestão de dados
O Microsoft Fabric Mirroring atualmente suporta SQL Server, Azure Cosmos DB e Oracle como sistemas de origem. Para fontes ainda não suportadas – como Sybase ou REST APIs – use pipelines do Fabric Data Factory para garantir cobertura completa.
Uma vez que os dados estão na zona de destino com o formato correto, a replicação CDC do Mirroring é iniciada automaticamente e gerencia a complexidade de mesclar alterações (updates, inserts, deletes) em tabelas Delta, mantendo os dados no Fabric continuamente atualizados. Saiba mais sobre open mirroring.
Formato de armazenamento e time travel
OneLake suporta tabelas Delta, permitindo schema evolution e time travel em todos os dados armazenados no lakehouse. Saiba mais sobre OneLake e Delta tables.
Segurança
- Encryption at rest: OneLake criptografa automaticamente todos os dados em repouso usando chaves gerenciadas pela Microsoft, em conformidade com FIPS 140-2.
- Encryption in transit: Todos os dados em trânsito são criptografados com TLS 1.2 ou superior, protegendo o movimento entre Fabric, OneLake e Azure Databricks. Saiba mais.
Governança de dados
OneLake pode ser registrado e escaneado pelo Microsoft Purview, permitindo catalogação de metadados e profiling de qualidade de dados. Isso protege informações sensíveis, incluindo PHI e PII, em todo o fluxo de ingestão e analytics. Saiba mais sobre Purview com Fabric Lakehouse.
Operações e monitoramento
Use o Fabric monitor hub para acompanhar a saúde dos pipelines, desempenho de aplicações Spark e status de jobs de ingestão em todas as workloads do Fabric. Saiba mais sobre o Fabric monitor hub.
Para quem essa arquitetura faz sentido?
Esta arquitetura se aplica a qualquer organização que precise unificar dados streaming e batch em escala. Características comuns incluem:
- Múltiplas fontes de dados operacionais (bancos de dados, aplicações SaaS, streams de eventos)
- Necessidade de processar dados em tempo real e históricos na mesma plataforma
- Requisitos de governança e conformidade para dados sensíveis (PHI, PII, registros financeiros)
- Consumidores de analytics que vão desde BI (Power BI) até data science (Databricks notebooks) e workloads de ML
Casos de uso potenciais
- Saúde e ciências da vida – Proteção de PHI/PII via Purview; telemetria de pacientes em tempo real + analytics batch de prontuários eletrônicos.
- Serviços financeiros – Streams de detecção de fraudes em tempo real + relatórios regulatórios batch.
- Varejo e e-commerce – Analytics streaming de clickstream + processamento batch de inventário e supply chain.
- Energia e utilities – Streaming de telemetria de sensores IoT + analytics batch de consumo.
Próximos passos
- Comece com Microsoft Fabric Mirroring
- Construa um pipeline ETL com Lakeflow Declarative Pipelines
- Configure Unity Catalog com OneLake shortcuts
- Monitore pipelines Fabric com o Fabric monitor hub
Perguntas Frequentes
-
Quais fontes de dados o Fabric Mirroring suporta atualmente?
O Mirroring suporta SQL Server, Azure Cosmos DB e Oracle como fontes operacionais. Para fontes não suportadas, como Sybase ou REST APIs, deve-se usar pipelines do Fabric Data Factory para garantir cobertura completa. -
Como funciona o time travel no OneLake e por que é relevante?
OneLake utiliza tabelas Delta, que permitem schema evolution e time travel. Isso possibilita consultar versões anteriores dos dados sem custo adicional de replicação, essencial para auditoria e recuperação de cenários de erro. -
Qual a diferença entre os caminhos 4 e 5 de integração?
O caminho 4 (OneLake to Azure Databricks) usa conexões do Unity Catalog via Managed Identities para acessar dados do OneLake sem duplicação. Já o caminho 5 (Fabric Data Factory direto para Azure Databricks) envia dados diretamente ao ADLS, onde o Databricks inicia o processamento medallion. -
Como garantir a governança de dados sensíveis como PHI e PII nessa arquitetura?
OneLake pode ser registrado e escaneado pelo Microsoft Purview, que cataloga metadados e perfila qualidade de dados. A criptografia em repouso (FIPS 140-2) e em trânsito (TLS 1.2+) também protege dados sensíveis em todo o fluxo. -
Essa arquitetura é adequada para empresas brasileiras que precisam de conformidade com a LGPD?
Sim, pois oferece criptografia, governança via Purview e controle de acesso via Managed Identities. A capacidade de time travel e lineage ajuda a demonstrar rastreabilidade exigida pela LGPD, especialmente em setores como saúde e financeiro.
Artigo originalmente publicado por Oscar Alvarado e Rafia Aqil em Azure Updates - Latest from Azure Charts.
