

TL;DR: Este artigo apresenta a nova funcionalidade activity insights dos Storage Insights datasets no Google Cloud, que fornece visibilidade quase em tempo real sobre operações em objetos e buckets. Com ela, empresas brasileiras podem identificar objetos em classes de armazenamento inadequadas, analisar padrões de tráfego entre regiões e diagnosticar erros como 429. A conclusão principal: dados de atividade são essenciais para transformar armazenamento passivo em ativo estratégico de FinOps e operações.
À medida que os footprints de armazenamento corporativo escalam para bilhões de objetos, aplicações de IA e workloads agentic estão transformando o papel do armazenamento – de repositório passivo para a fundação da plataforma de dados. Esse movimento é impulsionado pelo aumento de dados não estruturados de modelos e pelos bilhões de ações realizadas nesses objetos, incluindo logs de sessão e trilhas de auditoria. Para gerenciar tudo isso e responder a perguntas sobre custo, operações e segurança, administradores de storage e plataforma precisam ir além de saber quais dados possuem: é essencial entender exatamente como esses dados estão sendo acessados, movidos e modificados.
Para ajudar nessa missão, a Google anunciou o activity insights dentro dos Storage Insights datasets, agora em disponibilidade geral (GA). Essas novas visualizações fornecem visibilidade sobre os detalhes operacionais dos seus assets no Cloud Storage, permitindo otimização de custos baseada em dados e troubleshooting mais rápido. Com os activity insights, você pode responder perguntas como:
- Meus objetos estão nas classes de armazenamento corretas dentro dos meus buckets?
- Com quais regiões meu bucket mais interage – e será que ele está localizado de forma otimizada?
- Onde estão ocorrendo erros nas operações do meu storage estate e por quê?
Responder a essas perguntas com confiança é a chave para desbloquear otimizações de custo e recuperar tempo de engenharia. Storage Insights datasets – funcionalidade do Storage Intelligence para Cloud Storage – fornece metadados diários e activity insights frequentes (tipicamente dentro de quatro horas da atividade) para que você tenha visibilidade real do seu storage estate. Enquanto o Storage Intelligence é um produto de gerenciamento unificado com recursos como Bucket relocation, Batch operations e Gemini Cloud Assist, este artigo foca em como você pode aproveitar os Storage Insights datasets para otimização operacional.
O que são Storage Insights datasets?
Storage Insights datasets entregam um índice BigQuery automatizado e pronto para consulta de todo o seu storage estate, completo com metadados brutos e activity insights. Isso substitui a coleta manual e propensa a erros de dados. Os datasets podem ser customizados em escopo: crie um dataset para toda a organização, uma pasta específica, um projeto, um conjunto de projetos ou buckets específicos. O dataset é atualizado regularmente, oferecendo uma visão abrangente do seu armazenamento.
De metadados estáticos para inteligência dinâmica
Storage Insights datasets é a ferramenta ideal para entender os metadados do seu storage: atua como um inventário, escaneando metadados de objetos (storage class, localização, idade, metadados customizados) e organizando-os em um dataset poderoso e consultável no BigQuery. Isso é crucial para saber o que você tem (leia mais sobre otimização de gastos com Storage Insights datasets aqui).
Mas e se você também soubesse como e quando esses dados estão sendo usados?
Storage Insights datasets agora oferece novas visualizações que capturam:
- Atividade no nível do objeto, incluindo writes, updates, deletes e erros.
- Atividade agregada no nível do bucket, incluindo total de operações em objetos, detalhamento por tipo de operação, total de erros e prefixes mais ativos.
- Atividade de tráfego regional no nível do bucket, incluindo bytes de ingress e egress por região que interage com seu bucket.
- Atividade agregada no nível do projeto, incluindo total de operações, detalhamento por tipo e total de erros.
Esses dados fluem diretamente para novas views BigQuery dentro do seu dataset, permitindo consultas analíticas específicas, interação via Gemini ou conexão com Looker dashboards para visualização. Isso move você de um snapshot estático para uma análise dinâmica e consultável de todo o ciclo de vida dos dados. É a diferença entre saber o que está no seu armazém e saber o que é usado e quando.
Três formas de usar activity insights imediatamente
Aqui está o que você pode fazer, a partir de hoje, com os activity insights nos Storage Intelligence datasets.
1. Right-size sua storage estate
- O desafio: Você tem terabytes de dados em Standard ou Nearline que acredita serem frios. Mas sem comprovação, mover para Coldline ou Archive é arriscado. E se um processo crítico precisar ler esses dados uma vez por trimestre?
- A solução: Com as novas views que expõem activity insights, você identifica buckets com pouca ou nenhuma atividade de leitura/escrita nos últimos 30, 60 ou 90 dias.
- O resultado: Aplique ou ajuste políticas de ciclo de vida para transicionar esses dados para classes de armazenamento mais econômicas.
Por exemplo, a query SQL abaixo lista todos os buckets da sua organização com baixa atividade nos últimos seis meses:
SELECT name, location, project, totalRequests
FROM
`[project]`.`[dataset]`.`bucket_activity_view`
WHERE
snapshotEndTime >= TIMESTAMP(DATE_SUB(DATE_TRUNC(CURRENT_DATE(), MONTH), INTERVAL 5 MONTH))
AND snapshotEndTime < CURRENT_TIMESTAMP()
ORDER BY totalRequests ASC
//Running queries in Datasets accrues BQ query costs, refer to the pricing page for further details.
2. Arquitetura para performance global com data-driven bucket placement
- O desafio: Sua equipe configurou um bucket multi-região para atender uma aplicação global. Mas um ano depois, essa ainda é a arquitetura correta? E se 99% do tráfego agora vem de uma única região?
- A solução: Analise os padrões de acesso na nova tabela
bucket_region_activity_view. Você pode identificar rapidamente quais regiões estão gerando atividade de leitura e escrita no bucket. - O resultado: Tome decisões baseadas em dados para co-localizar seu bucket com seu compute. Pode ser que trocar um bucket multi-região por um single-region (ou vice-versa) gere economia significativa de custos e até melhore a performance.
Exemplo de query SQL para analisar tráfego de egress e ingress de um bucket entre regiões:
SELECT
requestLocation,
bucketLocation,
SUM(requestBytes) AS total_request_bytes,
SUM(responseBytes) AS total_response_bytes
FROM
`[project]`.`[dataset]`.`bucket_region_activity_view`
WHERE
name = '[bucket name]'
GROUP BY
requestLocation,
bucketLocation;
//Running queries in Datasets accrues BQ query costs, refer to the pricing page for further details.
Shipt, plataforma de tecnologia de varejo e entrega no mesmo dia, já utiliza as capacidades do Storage Intelligence para informar suas decisões de localização de dados:
“Storage Intelligence nos permite gerenciar eficientemente mais de 2 bilhões de objetos, entregando otimização de custo e performance. Com Insights datasets, detectamos e analisamos cobranças de egress de buckets multi-região, identificando oportunidades de melhoria ao co-localizar compute e storage. Aproveitando o recurso Bucket Relocate, movemos 1,3 Petabytes de dados de multi-região para regional storage, obtendo economia substancial de custos sem interromper a performance da aplicação ou a continuidade dos pipelines de dados.” — Ron Cuirle, Director of Engineering - Cloud Platforms, Shipt
3. Desvende e resolva hotspots operacionais
- O desafio: Sua equipe vê um pico de erros 429 (too many requests). Em ambientes massivos, isso raramente é um mico de performance — é caro! Esses erros disparam retentativas automáticas, que geram um ciclo de operações de alta frequência e faturáveis, elevando seus custos Classe A. Identificar exatamente qual objeto ou prefix está causando isso é um pesadelo de troubleshooting.
- A solução: As novas views dos Storage Insights datasets fornecem detalhes granulares sobre esses erros, diretamente no BigQuery. Você pode consultar erros 429 e ver exatamente quais objetos e prefixes estão sob pressão.
- O resultado: Além de identificar a origem dos erros, você descobre a causa (errorReason), movendo sua equipe do troubleshooting para a resolução.
Exemplo de query SQL para analisar erros 429 em todo o seu estate:
SELECT
requestOperation,
errorReason,
objectName,
bucketName,
requestCompletionTimestamp,
project
FROM
`[project]`.`[dataset]`.`object_events_view`
WHERE
responseStatus = 429
ORDER BY
requestCompletionTimestamp DESC;
//Running queries in Datasets accrues BQ query costs, refer to the pricing page for further details.
Como começar?
À medida que sua organização cresce no Google Cloud, a escala dos seus dados só aumenta. Pare de confiar em dados arquivados e comece a otimizar seu storage estate. Cloud Storage Storage Insights datasets com activity insights transformam enormes volumes de dados — antes desafios operacionais complexos — em ativos claramente compreendidos e altamente otimizados.
Para começar, use nosso template pré-configurado do Looker Studio aqui para conectar ao seu dataset e obter análises rápidas:
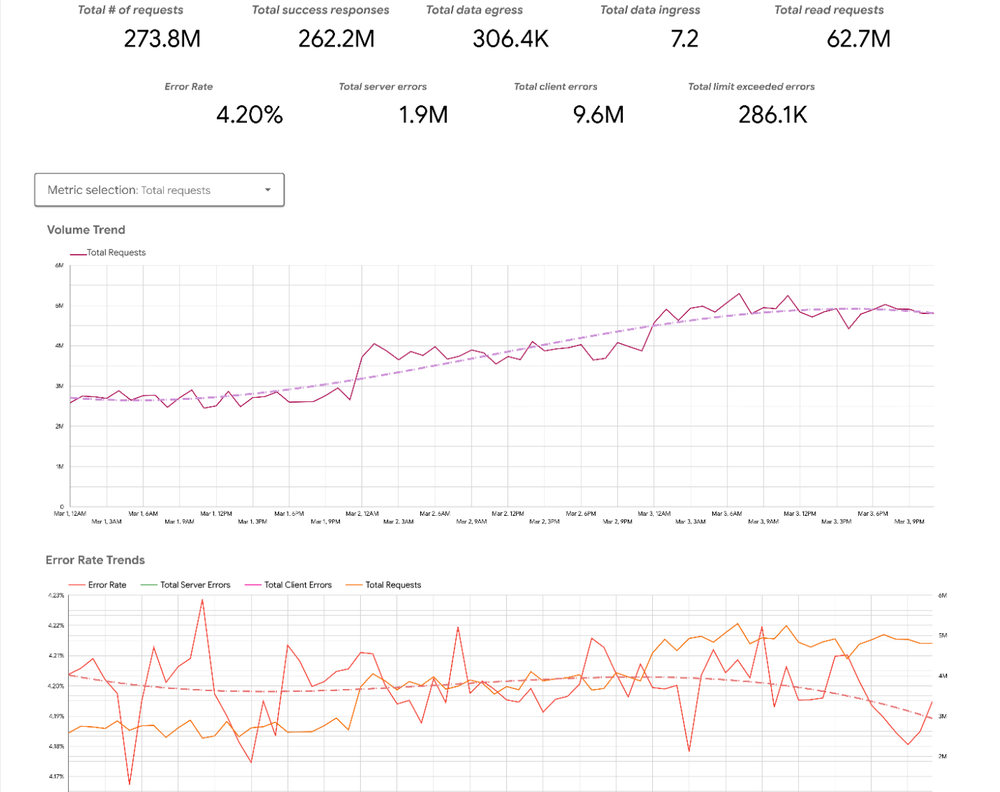
Ou analise os padrões de tráfego de ingress e egress do seu bucket:
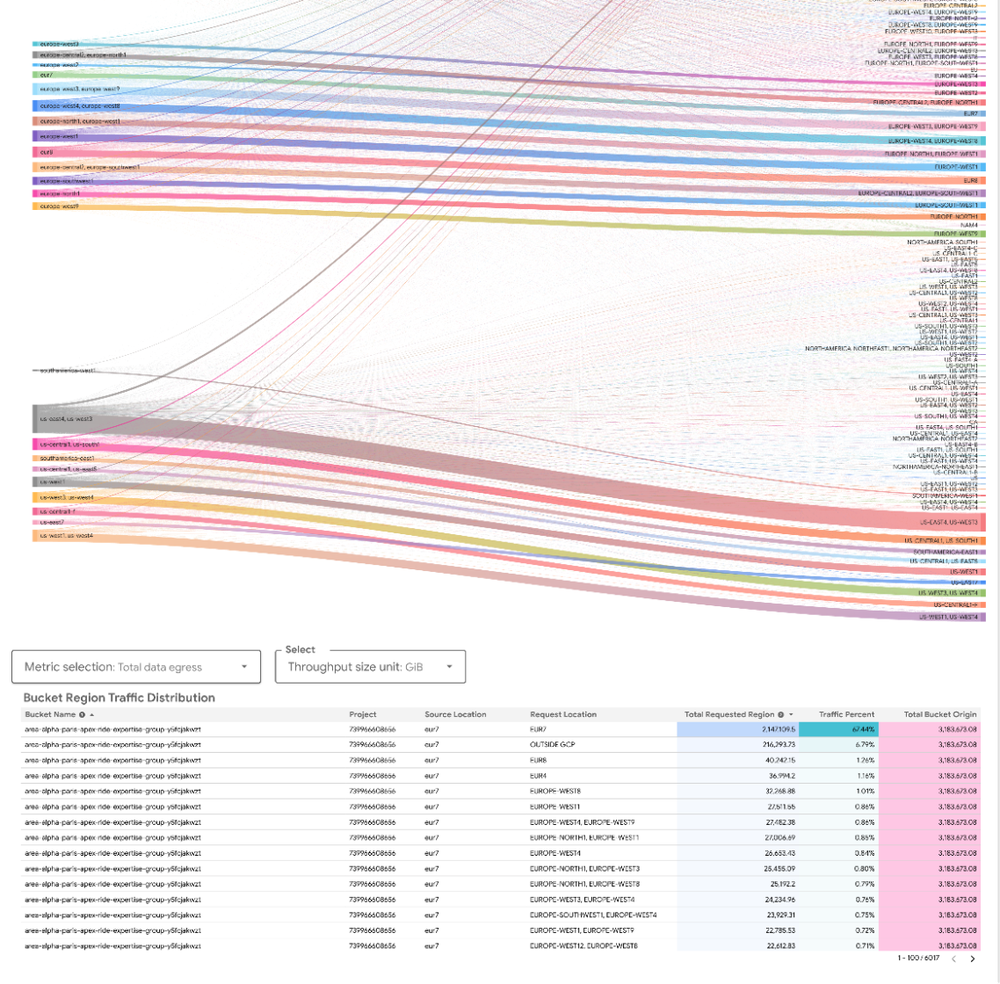
Pronto para transformar insight em ação?
- Ative o Storage Intelligence hoje no console do Google Cloud.
- Configure seu dataset e consulte seus dados diretamente no BigQuery ou conecte-se ao template Looker para visualização rápida.
- Assista aos vídeos sobre Storage Intelligence e How to Get Started.
- Leia mais sobre como otimizar seu footprint de Cloud Storage com Storage Insights datasets.
Perguntas Frequentes
-
Qual a diferença entre as visualizações de metadados e as de activity insights?
- Metadados mostram o que você tem (storage class, localização, idade), enquanto activity insights mostram como e quando os dados são acessados (operações de leitura, escrita, deleção e erros). Juntos, permitem decisões baseadas em uso real, não apenas em inventário.
-
Com que frequência os dados de atividade são atualizados?
- Os activity insights são tipicamente atualizados dentro de quatro horas após a atividade ocorrer, enquanto os metadados são atualizados diariamente. Isso oferece uma visão quase em tempo real das operações no seu storage estate.
-
É possível customizar o escopo do dataset?
- Sim. Você pode criar datasets para toda a organização, pastas específicas, projetos individuais, um conjunto de projetos ou até buckets específicos. O dataset é atualizado automaticamente e os dados ficam disponíveis no BigQuery para consultas.
-
Como identificar erros 429 (too many requests) no meu ambiente?
- Use a view
object_events_viewdo dataset e filtre porresponseStatus = 429. A consulta retorna a operação, o objeto, o bucket e o motivo do erro (errorReason), facilitando a correção de hotspots operacionais que geram custos com retentativas.
- Use a view
-
Quais casos de uso são mais relevantes para empresas brasileiras?
- Redução de custos movendo dados frios para Archive ou Coldline com base em atividade real, análise de egress para evitar cobranças de transferência entre regiões (comum em arquiteturas multi-região), e troubleshooting rápido de erros que disparam retentativas e aumentam custos de operações Classe A.
Artigo originalmente publicado por Kumar Nachiketa, APAC Technology Practice Lead, Storage em Cloud Blog.
